Jahanpour Alipour, Leila Erfannia, Afsaneh Karimi and Ali Aliabadi
DOI: 10.4172/2157-7420.1000120
Media Aminian and Hamid Reza Naji
DOI: 10.4172/2157-7420.1000121
Yu Ding, Hui Xue, Ning Jin, Yiu-Cho Chung, Xin Liu, Yongqin Zhang and Orlando P. Simonetti
DOI: 10.4172/2157-7420.1000122
Karhunen-Loeve Transform (KLT) is widely used in signal processing. Yet the well-accepted result is that, the noise
Norshima Humaidi and Vimala Balakrishnan
DOI: 10.4172/2157-7420.1000123
One of the main problems in information security was human error due to improper human behaviour. Therefore, this preliminary study was conducted with aims to identify possible factors that can affect user’s compliance behaviour towards information security in terms of two aspects: management support and security technology. Two theories were integrated for development of research framework: I) Theory of Planned Behaviour; II) Theory of Acceptance Model. The respondents of this study were the health professionals and IT officers whereby 42 questionnaires were obtained and verified. Exploratory Factor Analysis (EFA) results revealed that the six factors were obtained: Transactional_Leadership_ Style, Transformational_Leadership_Style, ISP_Training_Support, PU_Security, PU_Security-Countermeasure and PEOU_ISPs. The higher loadings signalled the correlations of the indicated items with the factors on which they were loaded with each of the correspondence factors achieving score of alpha value above 0.80. According to the descriptive analysis, most of the respondents are agreed with all the indicated factors. The preliminary study facilitates researcher in developing new model that integrates TPB and TAM that can be used to increase knowledge of user’s compliance behaviour towards health information system’s security.
Ahmad LG, Eshlaghy AT, Poorebrahimi A, Ebrahimi M and Razavi AR
DOI: 10.4172/2157-7420.1000124
Abdullayeva Gulchin Gulhuseyn, Irada Mirzazadeh Khatam, Naghizade Ulker Rauf and Naghiyev Rauf Gasan
DOI: 10.4172/2157-7420.1000125
According to statistical data, a considerable increase in the number of acute carbon monoxide poisonings has been
Objective: The aim of this study was to analyze clinical communication factors and interruptions and to develop clinician-clinician and clinician-computer knowledge representation models. Methods: An ICU observational study was combined with medical error reported cases to address the above questions. Researchers shadowed the ICU team, for 55 hours during patient rounds, to capture 6 main communication factors. Simultaneously, a systematic literature search was conducted to identify and extract reported medical error cases caused by clinical communication problem. The search included patient safety data banks, literature databases, newspaper, and reported lawsuits. Results: Out of 242 reported communication errors, 100 cases resulted in active errors while only 13 cases resulted in13 near misses; most of those errors were reported in journal articles (n = 302). As to the observation data, the most frequent communicator during ICU patient rounds was the Attending Physicians. The ratio of interruptions caused by clinicians to technology-aided devices was 3:1 per patient visit. The mean frequency of an Attending Physician interacting with a computer was once per patient visit. Analyzing data from both sources, two communication models representing the clinical communication framework were developed. Conclusion: Clinical communication is essential for effective health care delivery and for improved care outcomes. To further understand clinical communication, primary and secondary data were collected and analyzed and as a result, clinician-clinician and clinician-computer interaction models were
Yang Xiang, Marja Talikka, Vincenzo Belcastro, Peter Sperisen, Manuel C. Peitsch, Julia Hoeng and Joe Whittaker
Motivation: Understanding biological processes requires tools for the exploratory analysis of multivariate data generated from in vitro and in vivo experiments. Part of such analyses is to visualise the interrelationships between observed variables. Results: We build on recent work using partial correlation, graphical Gaussian models, and stability selection to add divergence weighted independence graphs (DWIGs) to this toolbox. We measure all quantities in information units (bits and millibits), to give a common quantification of the strength of associations between variables and of the information explained by a fitted graphical model. The marginal mutual information (MI) and conditional MI between variables directly account for components of the information explained. The conditional MIs are displayed as edge weights in the independence graph of the variables, making the complete graph informative as to the unique association between those variables. The summary table of the information decomposition ‘total = explained + residual’ provides a simple comparison of graphical models suggested by different search routines, including stabilised versions. We demonstrate the relevance of the conditional MI statistics to the graphical model of the data by analysing simulated data from the insulin pathway with a known ground truth. Here the method of thresholding these statistics to suggest a network performs at least as well as several other network searching algorithms. In searching a biological data set for novel insight, we contrast the DWIGs from the fitted maximum weight spanning tree and from the fitted model of a stabilised ARACNE network. DWIG is a powerful tool for the display of properties of the fitted model or of the empirical data directly.
Martin Schenck, Oliver Politz and Philip Groth
Genomic mutations may result in severe diseases, e.g. cancer, a disease with a significant genetic component. The mutation state of cancer tissues is e.g. being determined experimentally in order to find the most likely response to a drug treatment. Results of such experiments are typically published in scientific literature. We have developed a workflow of several text-mining algorithms, in order to harvest this wealth of information relevant to developing novel therapeutic approaches in cancer. Our workflow has successfully scanned over 150,000 abstracts related to cancer and genetic mutations. New information on mutated genes in cancer could be extracted with a precision and recall of 86.8% and 30.3%, respectively. By applying the workflow, novel associations of mutations in specific cancer tissues could be extracted for 264 genes.
Qing T. Zeng, Doug Redd, Guy Divita, Samah Jarad, Cynthia Brandt and Jonathan R. Nebeker
Objective: To characterize text and sublanguage in medical records to better address challenges within Natural Language Processing (NLP) tasks such as information extraction, word sense disambiguation, information retrieval, and text summarization. The text and sublanguage analysis is needed to scale up the NLP development for large and diverse free-text clinical data sets. Design: This is a quantitative descriptive study which analyzes the text and sublanguage characteristics of a very large Veteran Affairs (VA) clinical note corpus (569 million notes) to guide the customization of natural language processing (NLP) of VA notes. Methods: We randomly sampled 100,000 notes from the top 100 most frequently appearing document types. We examined surface features and used those features to identify sublanguage groups using unsupervised clustering. Results: Using the text features we are able to characterize each of the 100 document types and identify 16 distinct sublanguage groups. The identified sublanguages reflect different clinical domains and types of encounters within the sample corpus. We also found much variance within each of the document types. Such characteristics will facilitate the tuning and crafting of NLP tools. Conclusion: Using a diverse and large sample of clinical text, we were able to show there are a relatively large number of sublanguages and variance both within and between document types. These findings will guide NLP development to create more customizable and generalizable solutions across medical domains and sublanguages.
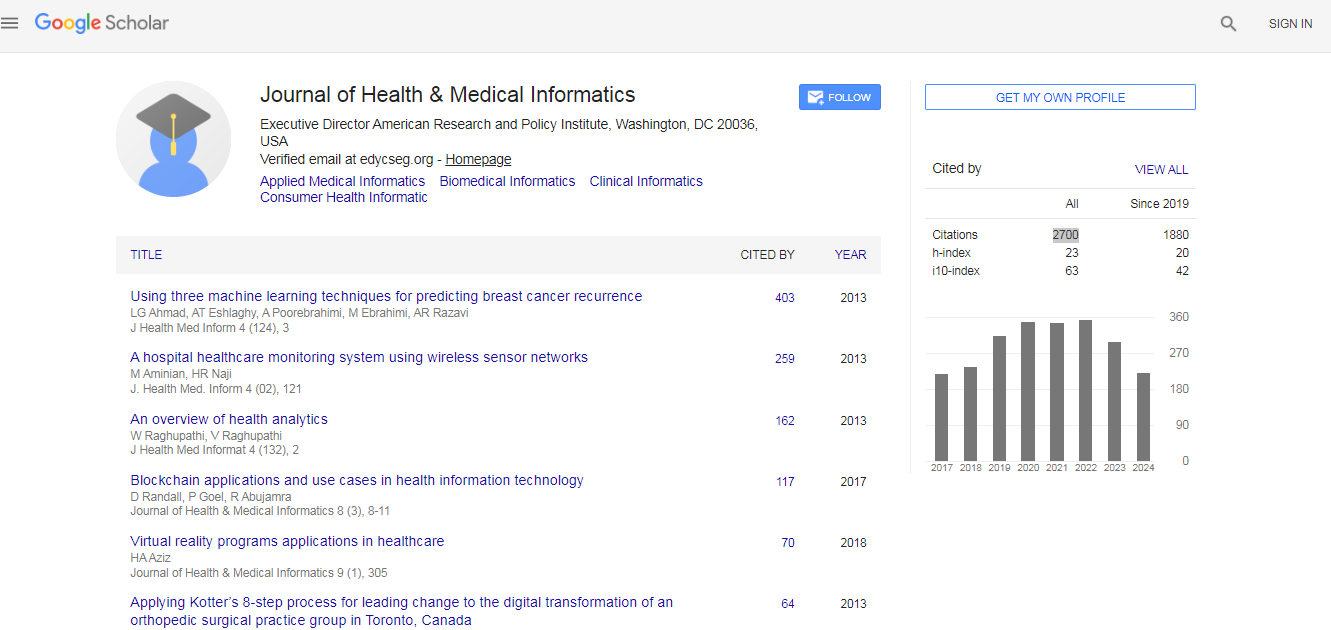
Journal of Health & Medical Informatics received 2128 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 