|
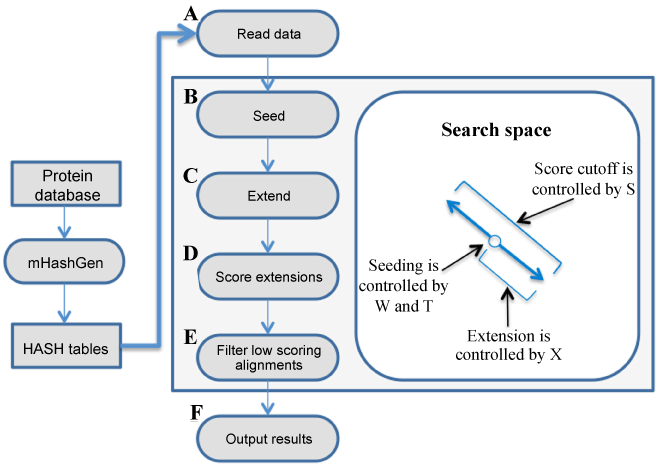
| Figure 1: The processing steps in the mBLASTX workflow. The database is first indexed using the mHashGen module and these index files are used in the alignment process. The query files are reads (A) and matching seeds between the queries and subjects are identified (B). These matches are then extended to high scoring segment pairs (C). These extensions are evaluated (D) and only significant alignments are kept (E) and displayed in the output (F). |