|
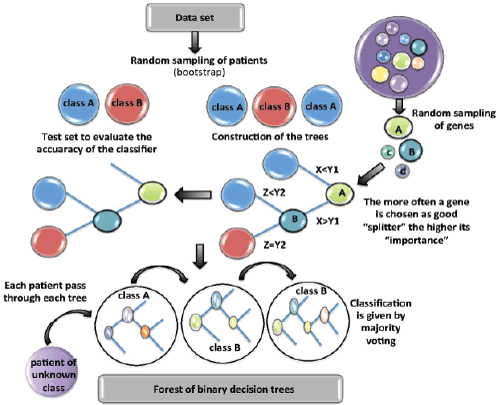
| Figure 2: An illustration of Random Forest. A Random Forest is a collection of decision trees. Each tree cast a vote in classifying and it is formed by first selecting at random, at each node, a small group of input features (genes) to split on and, secondly, by calculating the best split based on these features in the training set. The tree is grown to maximum size (without pruning). This randomization scheme is blended with bootstrap to resample, the training data set each time a new individual tree is grown. Each patient not used in the construction of the tree is used as test set (out of bag), the tree is then tested against the “out of bag” patients to estimate the accuracy of the classifier. The entire process is repeated with new random data set divisions and new random gene sets for selection of splitter variables to produce ultimately a forest. The forest can then also be applied to independent patients of unknown class. |