| Scenario 1a: Correctly Specified Model for Intercepts | ||||||||||||
| Complete-case MLE | MLE | Pseudo-conditional Likelihood Method | ||||||||||
| θ(0) =0.35 | 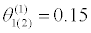 |
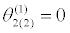 |
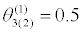 |
θ(0)=0.35 | 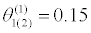 |
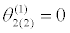 |
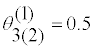 |
θ(0)=0.35 | 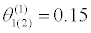 |
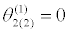 |
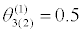 |
|
| Mean | 0.357 | 0.149 | 0 | 0.497 | 0.354 | 0.147 | 0.001 | 0.498 | 0.351 | 0.148 | 0.002 | 0.5 |
| Median | 0.353 | 0.149 | 0.003 | 0.498 | 0.349 | 0.146 | 0.004 | 0.496 | 0.348 | 0.146 | 0.005 | 0.498 |
| MAD | 0.17 | 0.157 | 0.161 | 0.154 | 0.127 | 0.13 | 0.123 | 0.128 | 0.129 | 0.133 | 0.129 | 0.127 |
| Emp. SE | 0.161 | 0.152 | 0.153 | 0.158 | 0.126 | 0.128 | 0.125 | 0.126 | 0.129 | 0.132 | 0.128 | 0.128 |
| Est. SE | 0.163 | 0.153 | 0.152 | 0.159 | 0.129 | 0.125 | 0.124 | 0.129 | 0.131 | 0.128 | 0.128 | 0.133 |
| Bias | 0.007 | −0.001 | 0 | −0.003 | 0.004 | −0.003 | 0.001 | −0.002 | 0.001 | −0.002 | 0.002 | −0.000 |
| B. Score | 1.985 | −0.189 | 0.046 | −0.720 | 1.406 | −0.904 | 0.455 | −0.791 | 0.448 | −0.550 | 0.693 | −0.064 |
| RMSE | 0.161 | 0.152 | 0.153 | 0.158 | 0.127 | 0.128 | 0.125 | 0.126 | 0.129 | 0.132 | 0.128 | 0.128 |
| CP | 0.948 | 0.955 | 0.952 | 0.949 | 0.958 | 0.949 | 0.948 | 0.956 | 0.95 | 0.948 | 0.951 | 0.963 |
| Scenario 1a: Correctly Specified Model for Intercepts | ||||||||||||
| Complete-case MLE | MLE | Pseudo-conditional Likelihood Method | ||||||||||
| θ(0) =0.35 | |
|
|
θ(0)=0.35 | |
|
|
θ(0)=0.35 | |
|
|
|
| Mean | 0.475 | 0.027 | −0.077 | 0.456 | 0.476 | 0.023 | −0.076 | 0.459 | 0.383 | 0.122 | −0.017 | 0.482 |
| Median | 0.478 | 0.031 | −0.077 | 0.451 | 0.476 | 0.022 | −0.075 | 0.457 | 0.383 | 0.12 | −0.016 | 0.479 |
| MAD | 0.147 | 0.146 | 0.155 | 0.147 | 0.117 | 0.125 | 0.124 | 0.122 | 0.133 | 0.13 | 0.134 | 0.124 |
| Emp. SE | 0.148 | 0.15 | 0.152 | 0.152 | 0.117 | 0.122 | 0.124 | 0.122 | 0.133 | 0.128 | 0.13 | 0.127 |
| Est. SE | 0.159 | 0.149 | 0.149 | 0.155 | 0.126 | 0.122 | 0.122 | 0.125 | 0.136 | 0.128 | 0.127 | 0.132 |
| Bias | 0.125 | −0.123 | −0.077 | −0.044 | 0.126 | −0.127 | −0.076 | −0.041 | 0.033 | −0.028 | −0.017 | −0.018 |
| B. Score | 37.776 | −36.571 | −22.603 | −12.880 | 48.513 | −46.309 | −27.410 | −15.099 | 11.16 | −9.918 | −5.717 | −6.248 |
| RMSE | 0.194 | 0.194 | 0.171 | 0.158 | 0.172 | 0.176 | 0.145 | 0.129 | 0.137 | 0.131 | 0.131 | 0.129 |
| CP | 0.898 | 0.86 | 0.916 | 0.942 | 0.858 | 0.812 | 0.898 | 0.942 | 0.954 | 0.946 | 0.946 | 0.954 |