| V | R2 | 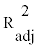 |
MCP | SE | A | L | G | Bas | B Ty | Y | Con | W | F |
| 1 | 2.1 | 1.5 | -0.8 | 0.33511 | X | ||||||||
| 1 | 1.1 | 0.5 | 0.8 | 0.33677 | X | ||||||||
| 2 | 2.9 | 1.7 | -0.2 | 0.33465 | X | X | |||||||
| 2 | 2.8 | 1.6 | -0.0 | 0.33481 | X | X | |||||||
| 3 | 3.7 | 1.9 | 0.5 | 0.33434 | X | X | X | ||||||
| 3 | 3.6 | 1.8 | 0.6 | 0.33446 | X | X | X | ||||||
| 4 | 4.6 | 2.2 | 1.1 | 0.33384 | X | X | X | X | |||||
| 4 | 4.0 | 1.6 | 2.0 | 0.33483 | X | X | X | X | |||||
| 5 | 5.0 | 2.0 | 2.4 | 0.33419 | X | X | X | X | X | ||||
| 5 | 4.8 | 1.8 | 2.8 | 0.33460 | X | X | X | X | X | ||||
| 6 | 5.2 | 1.6 | 4.1 | 0.33487 | X | X | X | X | X | X | |||
| 6 | 5.1 | 1.5 | 4.3 | 0.33511 | X | X | X | X | X | X | |||
| 7 | 5.2 | 1.0 | 6.0 | 0.33586 | X | X | X | X | X | X | X | ||
| 7 | 5.2 | 1.0 | 6.1 | 0.33591 | X | X | X | X | X | X | X | ||
| 8 | 5.3 | 0.4 | 8.0 | 0.33691 | X | X | X | X | X | X | X | X | |
| 8 | 5.2 | 0.4 | 8.0 | 0.33694 | X | X | X | X | X | X | X | X | |
| 9 | 5.3 | 0.0 | 10.0 | 0.3800 | X | X | X | X | X | X | X | X | X |
, Mallow’s Cp (MCP) and standard error (SE) in each subset is presented. V denotes the
number of factors included within each model.