|
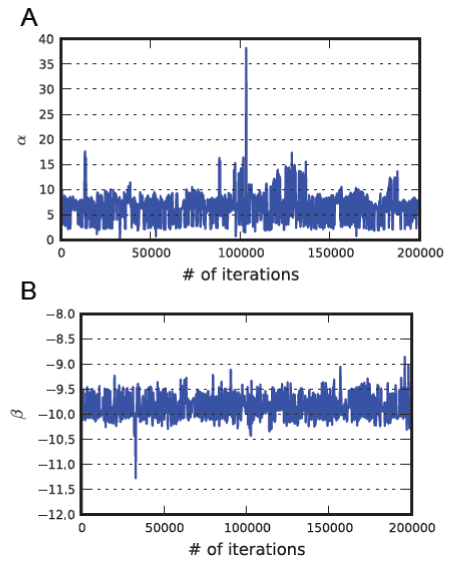
| Figure 5: Chains of random samples approximating the posterior distributions of the parameters α (panel A) and β (panel B) corresponding to the non-cancerous class of samples for the tag with ID 182-FIP (third row in Table 1). These samples were generated after 200K iterations of the algorithm. A similar pair of chains exists for each gene at each sample class (i.e. cancerous and non-cancerous), although not all pairs are distinct to each other due to the clustering effect imposed on the data by the algorithm. |