Nuzhat A Akram \r\n
Short Tandem Repeat (STR) markers are moderately repetitious DNA segments serving efficiently as a core sequence for the human identification. Their use as identification markers involves many technical and statistical issues. DNASF (DNA Statistics for Forensics) is a package of statistical programs designed to analyze the STR distribution in a heterogeneous population. It includes software DNA Forensics GenePro and DNA Forensics and a Microsoft excel workbook DNA AF. They can compute a number of parameters used to estimate the forensic utility of STR loci, including genetic diversity, unbiased heterozygosity, Shannon information index, polymorphism information content, and probability of exclusion and power of discrimination. In these programs each individual/ subpopulation is defined on the basis of two variables namely paternal ethnicity and mother tongue. The options for the two variables consist mainly of Indian subcontinent ethnicities and native languages but it does not undermine the software utility for researchers working on other populations. The input data are CODIS STR genotype and allele frequency data for DNA Forensics GenePro and DNA Forensics respectively. DNA AF can calculate allele frequency and other descriptive statistics from genotype data. Each component of DNASF is user friendly and provided with a set of instructions. For validation studies genotype data of five Pakistani subpopulations and allele frequency data of fifteen world populations were used. Validation studies of DNASF made it a reliable and effective tool for forensic investigations.
\r\n
Share this article
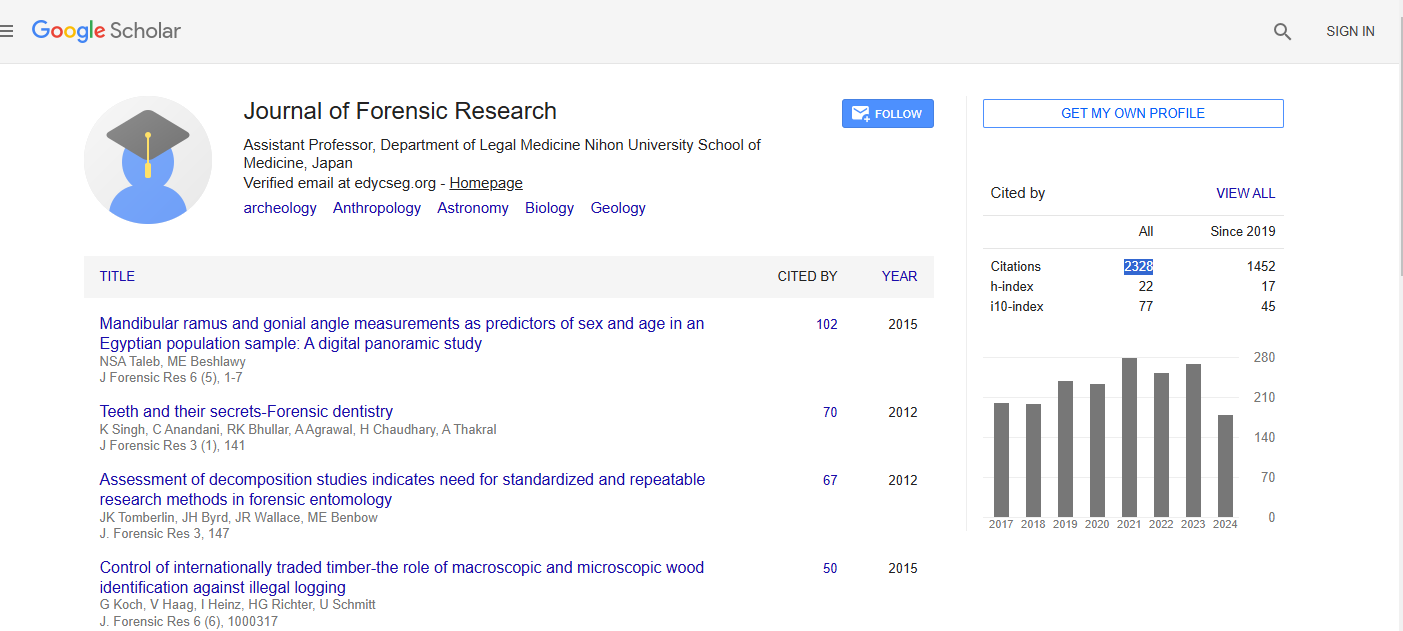
Journal of Forensic Research received 1817 citations as per Google Scholar report