Carlo Trugenberger
Keynote: J Mol Biomark Diagn
Background: Biomarkers and target-specific phenotypes are important to targeted drug design and individualized medicine. More and more, the discovery of relevant biomarkers is aided by in silico techniques based on applying data mining and computational chemistry on large molecular databases. However, there is an even larger source of valuable information available that can potentially be tapped for such discoveries: repositories constituted by research documents. Results: This paper reports on a pilot experiment to discover potential novel biomarkers and phenotypes for diabetes and obesity by self-organized text mining of about 120,000 PubMed abstracts, public clinical trial summaries, and internal Merck research documents. These documents were directly analyzed by the InfoCodex semantic engine, without prior human manipulations such as parsing. Retrieval of known entities missed by other traditional approaches could be demonstrated. Moreover, the InfoCodex semantic engine was shown to discover new diabetes and obesity biomarkers and phenotypes. Amongst these were many interesting candidates with a high potential, although noticeable noise (uninteresting or obvious terms) was generated. Conclusions: The reported approach of employing autonomous self-organising semantic engines to aid biomarker discovery, supplemented by appropriate manual curation processes, shows promise and has potential to impact pharmaceutical research, for example to shorten time-to-market of novel drugs, or speed up early recognition of dead ends and adverse reactions.
Carlo A. Trugenberger earned his Ph.D. in Theoretical Physics in 1988 at the Swiss Federal Institute of Technology, Z�rich and his Master in Economics in 1997 at Bocconi University, Milano. An international academic career in theoretical physics (MIT, Los Alamos Nat. Lab., CERN Geneva, Max Planck Institut M�nich) lead him to the position of associate professor of theoretical physics at Geneva University. In 2001 he decided to quit academia and to exploit his expertise in information theory, neural networks and machine intelligence to design an innovative semantic technology and to co-found the company InfoCodex Semantic Technologies AG. His scientific work has been recognized in the press and the semantic technology he co-designed has won International benchmarks and awards.
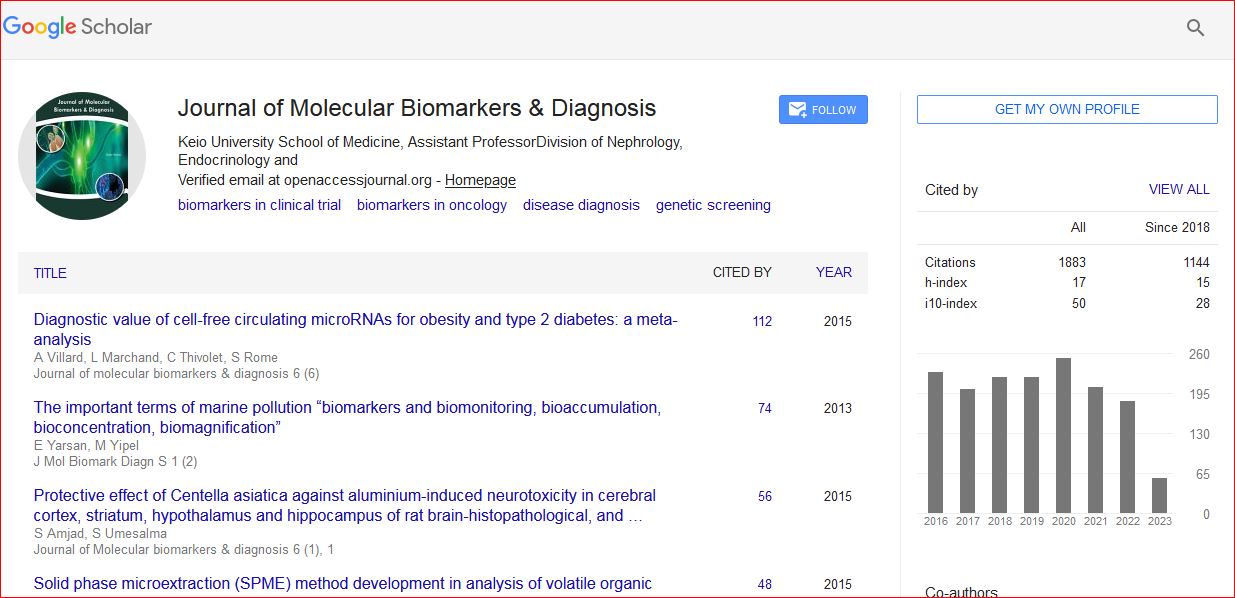
Journal of Molecular Biomarkers & Diagnosis received 2054 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 