 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi Our Group organises 3000+ Global Conferenceseries Events every year across USA, Europe & Asia with support from 1000 more scientific Societies and Publishes 700+ Open Access Journals which contains over 50000 eminent personalities, reputed scientists as editorial board members.
Open Access Journals gaining more Readers and Citations
700 Journals and 15,000,000 Readers Each Journal is getting 25,000+ Readers
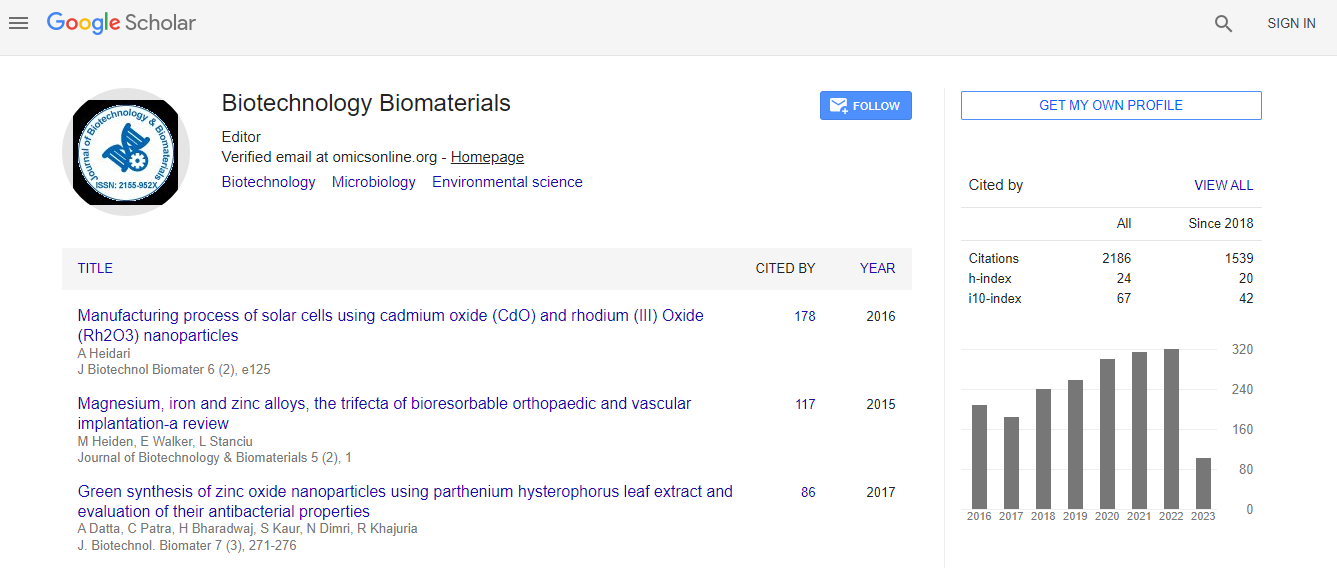
Google Scholar citation report
Citations : 3330
Journal of Biotechnology & Biomaterials received 3330 citations as per Google Scholar report
Indexed In
- Index Copernicus
- Google Scholar
- Sherpa Romeo
- Open J Gate
- Genamics JournalSeek
- Academic Keys
- ResearchBible
- China National Knowledge Infrastructure (CNKI)
- Access to Global Online Research in Agriculture (AGORA)
- Electronic Journals Library
- RefSeek
- Hamdard University
- EBSCO A-Z
- OCLC- WorldCat
- SWB online catalog
- Virtual Library of Biology (vifabio)
- Publons
- Geneva Foundation for Medical Education and Research
- Euro Pub
- ICMJE
Useful Links
Recommended Journals
Related Subjects
Share This Page
In Association with
PyMine - A PyMol plugin to integrate and visualize chemical and biological data for drug discovery
7th Asia-Pacific Biotech Congress
Zhijun Li and Rajan Chaudhari
ScientificTracks Abstracts: J Biotechnol Biomater